

Data#
- dispersionrelations.data.corr_to_cov(corr, std)[source]#
Convert a correlation matrix to a covariance matrix.
- Parameters:
- Returns:
cov – The resulting covariance matrix.
- Return type:
- Raises:
ValueError – If corr is not a square matrix or if corr and std have incompatible dimensions.
- dispersionrelations.data.cov_to_corr(cov)[source]#
Convert a covariance matrix to a correlation matrix.
- dispersionrelations.data.cov_to_std(cov)[source]#
Convert a covariance matrix to standard deviations (square root of the diagonal elements).
- dispersionrelations.data.std_to_cov(std, correlation=0.0)[source]#
Convert standard deviations to a covariance matrix, assuming a given correlation structure.
- Parameters:
std (array-like, shape (N,)) – The standard deviations to be converted.
correlation (float, optional) – The correlation coefficient to be used in the conversion. Default is 0.0 (no correlation).
- Returns:
cov – The resulting covariance matrix.
- Return type:
- Raises:
ValueError – If std is not a one-dimensional array.
- dispersionrelations.data.chi2(fit_data, observed_data, covariance_matrix, weights=None)[source]#
\(\chi^2\), computed using modelled and observed data.
- Parameters:
fit_data (array_like) – Data obtained from a model, \(f_i \in \{f_1, f_2, \dots, f_n\}\).
observed_data (array_like) – Data obtained from an experiment, \(o_i \in \{o_1, o_2, \dots, o_n\}\).
covariance_matrix (array_like) – Covariance matrix of the experimental data, \(C \in \mathbb{R}^{n\times n}\).
weights (array_like) – Weight matrix, used to manually attenuate parts of the data, \(W \in \mathbb{R}^{n\times n}\).
- Returns:
s – The total \(\chi^2\).
- Return type:
float
Notes
The \(\chi^2\) is calculated using
\[\chi^2 = \sum_i \sum_j (f_i-o_i)(C^{-1}_{ij}W_{ij})(f_j-o_j).\]See also
dispersionrelations.data.chi2_vectorfor individual contributions.
- dispersionrelations.data.chi2_with_inverse(fit_data, observed_data, inverse_covariance_matrix, weights=None)[source]#
\(\chi^2\), computed using modelled and observed data. This version of the function accepts the inverse of the covariance matrix as a parameter and therefore gains speed by avoiding matrix inversion.
- Parameters:
fit_data (array_like) – Data obtained from a model, \(f_i \in \{f_1, f_2, \dots, f_n\}\).
observed_data (array_like) – Data obtained from an experiment, \(o_i \in \{o_1, o_2, \dots, o_n\}\).
inverse_covariance_matrix (array_like) – Inverted covariance matrix of the experimental data, \(I \in \mathbb{R}^{n\times n}\).
weights (array_like) – Weight matrix, used to manually attenuate parts of the data, \(W \in \mathbb{R}^{n\times n}\).
- Returns:
s – The total \(\chi^2\).
- Return type:
float
Notes
The \(\chi^2\) is calculated using
\[\chi^2 = \sum_i \sum_j (f_i-o_i)(I_{ij}W_{ij})(f_j-o_j).\]See also
dispersionrelations.data.chi2_vector_with_inversefor individual contributions.
- dispersionrelations.data.chi2_vector(fit_data, observed_data, covariance_matrix, weights=None)[source]#
\(\chi^2\) vector.
- Parameters:
fit_data (array_like) – Data obtained from a model, \(f_i \in \{f_1, f_2, \dots, f_n\}\).
observed_data (array_like) – Data obtained from an experiment, \(o_i \in \{o_1, o_2, \dots, o_n\}\).
covariance_matrix (array_like) – Covariance matrix of the experimental data, \(C \in \mathbb{R}^{n\times n}\).
weights (array_like) – Weight matrix, used to manually attenuate parts of the data, \(W \in \mathbb{R}^{n\times n}\).
- Returns:
v – A vector with shape (n,) of individual \(\chi^2\) contributions.
- Return type:
array_like
Notes
The \(\chi^2\) vector is built using
\[v_i = \sum_j (f_i-o_i)(C^{-1}_{ij}W_{ij})(f_j-o_j).\]Warning
When the covariance matrix is non-diagonal, the individual components of this vector do not have a statistical meaning, since the observations are correlated. Use with caution!
Examples
>>> import numpy as np >>> from dispersionrelations.data import chi2_vector >>> np.random.seed(137) >>> n = 10 >>> x_f = np.linspace(1, 2, n) >>> x_o = x_f + 0.1 * np.random.rand(n) >>> x_e = 0.1 * (np.random.rand(n) + 1) / 2 >>> x_C = np.diag(x_e)**2 >>> print(chi2_vector(x_f, x_o, x_C)) [0.89280398 0.01007333 0.62584069 0.67718574 0.32026806 0.99981995 0.91740446 0.01387227 2.33635045 0.18841755]
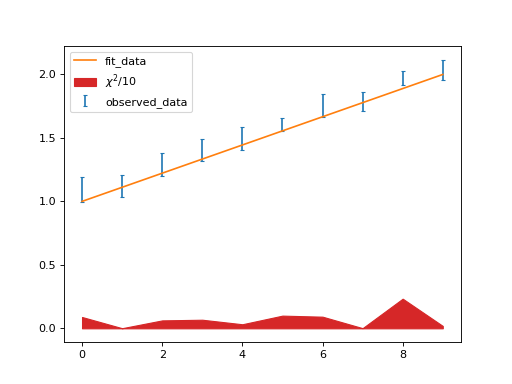
See also
- dispersionrelations.data.chi2_vector_with_inverse(fit_data, observed_data, inverse_covariance_matrix, weights=None)[source]#
\(\chi^2\), computed using modelled and observed data. This version of the function accepts the inverse of the covariance matrix as a parameter and therefore gains speed by avoiding matrix inversion.
- Parameters:
fit_data (array_like) – Data obtained from a model, \(f_i \in \{f_1, f_2, \dots, f_n\}\).
observed_data (array_like) – Data obtained from an experiment, \(o_i \in \{o_1, o_2, \dots, o_n\}\).
inverse_covariance_matrix (array_like) – Inverted covariance matrix of the experimental data, \(I \in \mathbb{R}^{n\times n}\).
weights (array_like) – Weight matrix, used to manually attenuate parts of the data, \(W \in \mathbb{R}^{n\times n}\).
- Returns:
v – A vector with shape (n,) of individual \(\chi^2\) contributions.
- Return type:
array_like
Notes
The \(\chi^2\) vector is built using
\[v_i = \sum_j (f_i-o_i)(I_{ij}W_{ij})(f_j-o_j).\]
- dispersionrelations.data.chi2_reduced(fit_data, observed_data, covariance_matrix, weights=None, number_of_parameters=0)[source]#
A reduced \(\chi^2\), computed using modelled and observed data.
- Parameters:
fit_data (array_like) – Data obtained from a model, \(f_i \in \{f_1, f_2, \dots, f_n\}\).
observed_data (array_like) – Data obtained from an experiment, \(o_i \in \{o_1, o_2, \dots, o_n\}\).
covariance_matrix (array_like) – Covariance matrix of the experimental data, \(C \in \mathbb{R}^{n\times n}\).
weights (array_like) – Weight matrix, used to manually attenuate parts of the data, \(W \in \mathbb{R}^{n\times n}\).
number_of_parameters (int) – Number of parameters in the model, used for calculating the degrees of freedom.
- Returns:
s – The reduced \(\chi^2\).
- Return type:
float
Notes
The reduced \(\chi^2\) is calculated using
\[\bar{\chi}^2 = \frac{\chi^2}{\text{d.o.f.}} = \frac{1}{n - n_\text{par}} \sum_i \sum_j (f_i-o_i)(C^{-1}_{ij}W_{ij})(f_j-o_j).\]See also
- dispersionrelations.data.chi2_reduced_with_inverse(fit_data, observed_data, inverse_covariance_matrix, weights=None, number_of_parameters=0)[source]#
A reduced \(\chi^2\), computed using modelled and observed data. This version of the function accepts the inverse of the covariance matrix as a parameter and therefore gains speed by avoiding matrix inversion.
- Parameters:
fit_data (array_like) – Data obtained from a model, \(f_i \in \{f_1, f_2, \dots, f_n\}\).
observed_data (array_like) – Data obtained from an experiment, \(o_i \in \{o_1, o_2, \dots, o_n\}\).
inverse_covariance_matrix (array_like) – Inverted covariance matrix of the experimental data, \(I \in \mathbb{R}^{n\times n}\).
weights (array_like) – Weight matrix, used to manually attenuate parts of the data, \(W \in \mathbb{R}^{n\times n}\).
number_of_parameters (int) – Number of parameters in the model, used for calculating the degrees of freedom.
- Returns:
s – The reduced \(\chi^2\).
- Return type:
float
Notes
The reduced \(\chi^2\) is calculated using
\[\bar{\chi}^2 = \frac{\chi^2}{\text{d.o.f.}} = \frac{1}{n - n_\text{par}} \sum_i \sum_j (f_i-o_i)(I_{ij}W_{ij})(f_j-o_j).\]See also
- class dispersionrelations.data.Datablock(x, y, xlabel, ylabel, cov_stat=None, cov_syst=None, metadata={})[source]#
Bases:
objectA class to represent a dataset with x and y values, along with statistical and systematic covariance matrices.
- Parameters:
x (array-like, shape (N,)) – The x values of the data points.
y (array-like, shape (N,)) – The y values of the data points.
cov_stat (array-like, shape (N, N), optional) – The initial statistical covariance matrix. Default is None, which initializes it to a zero matrix.
cov_syst (array-like, shape (N, N), optional) – The initial systematic covariance matrix. Default is None, which initializes it to a zero matrix.
metadata (dict, optional) – A dictionary to store additional metadata about the dataset. Default is an empty dictionary. Common keys include ‘ref’, ‘header’, ‘footer’, utilised by the
Datawriterclass.
- N#
The number of data points.
- Type:
int
- metadata#
A dictionary to store additional metadata about the dataset.
- Type:
dict
- check_cov_pd()[source]#
Check if the total covariance matrix (statistical + systematic) is positive definite. Display a warning if it is not.
- Return type:
None
- get_std_stat()[source]#
Get the statistical standard deviations (square root of the diagonal elements of the statistical covariance matrix).
- Returns:
std_stat – The statistical standard deviations.
- Return type:
array-like, shape (N,)
- get_std_syst()[source]#
Get the systematic standard deviations (square root of the diagonal elements of the systematic covariance matrix).
- Returns:
std_syst – The systematic standard deviations.
- Return type:
array-like, shape (N,)
- get_std_total(add_in_quadrature=True)[source]#
Get the total standard deviations (square root of the diagonal elements of the total covariance matrix).
- Parameters:
add_in_quadrature (bool, optional) – If True, compute the total standard deviations by adding the statistical and systematic standard deviations in quadrature. If False, compute the total standard deviations from the total covariance matrix. Default is True.
- Returns:
std_total – The total standard deviations.
- Return type:
array-like, shape (N,)
- add_std_stat(std_stat, correlation=0.0)[source]#
Add a contribution to the statistical covariance matrix from standard deviations.
- Parameters:
std_stat (array-like, shape (N,) or scalar) – The standard deviations to be converted to covariance matrix.
correlation (float, optional) – The correlation coefficient to be used in the conversion. Default is 0.0 (no correlation).
- Return type:
None
- Raises:
ValueError – If std_stat is not a scalar or of shape (N,).
- add_rel_stat(rel_stat, correlation=0.0)[source]#
Add a contribution to the statistical covariance matrix from relative uncertainties.
- Parameters:
rel_stat (array-like, shape (N,) or scalar) – The relative uncertainties to be converted to standard deviations.
correlation (float, optional) – The correlation coefficient to be used in the conversion. Default is 0.0 (no correlation).
- Return type:
None
- Raises:
ValueError – If rel_stat is not a scalar or of shape (N,).
- add_std_syst(std_syst, correlation=1.0)[source]#
Add a contribution to the systematic covariance matrix from standard deviations.
- Parameters:
std_syst (array-like, shape (N,) or scalar) – The standard deviations to be converted to covariance matrix.
correlation (float, optional) – The correlation coefficient to be used in the conversion. Default is 1.0 (full correlation).
- Return type:
None
- Raises:
ValueError – If std_syst is not a scalar or of shape (N,).
- add_rel_syst(rel_syst, correlation=1.0)[source]#
Add a contribution to the systematic covariance matrix from relative uncertainties.
- Parameters:
rel_syst (array-like, shape (N,) or scalar) – The relative uncertainties to be converted to standard deviations.
correlation (float, optional) – The correlation coefficient to be used in the conversion. Default is 1.0 (full correlation).
- Return type:
None
- Raises:
ValueError – If rel_syst is not a scalar or of shape (N,).
- add_external_calibration(c, c_std, correlation=1.0, new_ylabel=None)[source]#
Apply an external calibration factor to the data and propagate its uncertainty.
- Parameters:
c (float) – The calibration factor to be applied to the data.
c_std (float) – The uncertainty of the calibration factor.
correlation (float, optional) – The correlation coefficient to be used in the propagation of the calibration uncertainty. Default is 1.0 (full correlation).
new_ylabel (str, optional) – The new label for the y-axis after calibration. If None, the label remains unchanged.
- Return type:
None
- Raises:
ValueError – If c or c_std is not a scalar.
Notes
For x-dependent calibration factors, use rescale_y instead.
- rescale_y(factor, factor_std=None, stat_or_syst='syst', correlation=0.0, new_ylabel=None)[source]#
Rescale the y values by a given factor without propagating the uncertainty.
- Parameters:
factor (array-like, shape (N,)) – The factor by which to rescale the y values. If an array is provided, it must be of shape (N,).
factor_std (array-like, shape (N,)) – The uncertainty of the rescaling factor (not propagated).
stat_or_syst (str, optional) – Specify whether the uncertainty is ‘stat’ (statistical) or ‘syst’ (systematic). Default is ‘syst’.
correlation (float, optional) – The correlation coefficient to be used for the uncertainty propagation. Default is 0.0 (no correlation).
new_ylabel (str, optional) – The new label for the y-axis after rescaling. If None, the label remains unchanged
- Return type:
None
- Raises:
ValueError – If factor is not a scalar or of shape (N,).
Notes
For a global rescaling, use add_external_calibration instead.
- filter_data(mask)[source]#
Filter the data based on a boolean mask.
- Parameters:
mask (array-like, shape (N,)) – A boolean array indicating which data points to keep.
- Return type:
None
- Raises:
ValueError – If mask is not of length N.
- filter_xrange(x_min=None, x_max=None)[source]#
Filter the data based on x range.
- Parameters:
x_min (float, optional) – The minimum x value to keep. If None, no lower bound is applied.
x_max (float, optional) – The maximum x value to keep. If None, no upper bound is applied.
- Return type:
None
- filter_yrange(y_min=None, y_max=None)[source]#
Filter the data based on y range.
- Parameters:
y_min (float, optional) – The minimum y value to keep. If None, no lower bound is applied.
y_max (float, optional) – The maximum y value to keep. If None, no upper bound is applied.
- Return type:
None
- remove_datapoints(indices)[source]#
Remove data points based on their indices.
- Parameters:
indices (array-like, shape (M,)) – An array of indices of the data points to be removed.
- Return type:
None
- Raises:
ValueError – If any index is out of bounds.
- downsample_by(factor)[source]#
Downsample the data by a given factor.
- Parameters:
factor (int) – The downsampling factor. Must be a positive integer.
- Return type:
None
- Raises:
ValueError – If factor is not a positive integer.
- downsample_to(N_points)[source]#
Downsample the data to a given number of points.
- Parameters:
N_points (int) – The desired number of data points after downsampling. Must be a positive integer less than or equal to N.
- Return type:
None
- Raises:
ValueError – If N_points is not a positive integer or greater than N.
- class dispersionrelations.data.Datawriter(datablock, file_prefix, folder_path='', quiet=False, format={'delimiter': '\t', 'fmt': '% .11e'})[source]#
Bases:
objectA class for writing Datablock data to files.
- Parameters:
datablock (Datablock) – The Datablock object containing the data to be written.
file_prefix (str) – The prefix for the output files.
folder_path (str, optional) – The folder path where the files will be saved. Default is the current directory. If the folder does not exist, it will be created.
quiet (bool, optional) – If True, suppresses output messages. Default is False.
format (dict, optional) – A dictionary specifying the format for saving the data.
- write_data(**filekwargs)[source]#
Write the data to a .dat file. The file will contain columns for x, y, statistical uncertainty, and systematic uncertainty.
- Parameters:
filekwargs (dict) – Additional keyword arguments to be passed to np.savetxt.
- Return type:
None
- write_cov_stat(**filekwargs)[source]#
Write the statistical covariance matrix to a .dat file. The file will contain the statistical covariance matrix.
- Parameters:
filekwargs (dict) – Additional keyword arguments to be passed to np.savetxt.
- Return type:
None
- write_cov_syst(**filekwargs)[source]#
Write the systematic covariance matrix to a .dat file. The file will contain the systematic covariance matrix.
- Parameters:
filekwargs (dict) – Additional keyword arguments to be passed to np.savetxt.
- Return type:
None
- write_all(**filekwargs)[source]#
Write all data to .dat files. This includes the main data file, the statistical covariance matrix file, and the systematic covariance matrix file.
- Parameters:
filekwargs (dict) – Additional keyword arguments to be passed to np.savetxt. This argument is shared between all three writing functions. For a finer control, call the individual writing functions instead.
- Return type:
None
- class dispersionrelations.data.Datareader(folder, prefix)[source]#
Bases:
objectA class for reading Datablock data from files.
- Parameters:
folder (str) – The folder path where the files are located.
prefix (str) – The prefix for the input files.
- read_all(**filekwargs)[source]#
Read all data from .dat files and return a Datablock object. This includes the main data file, the statistical covariance matrix file, and the systematic covariance matrix file.
- Parameters:
filekwargs (dict) – Additional keyword arguments to be passed to np.loadtxt.
- Returns:
A Datablock object containing the data read from the files.
- Return type:
- Raises:
ValueError – If the shapes of the covariance matrices do not match the expected dimensions. If the uncertainties (squared) do not match the diagonals of the covariance matrices.